BERT-Large: Prune Once for DistilBERT Inference Performance

By A Mystery Man Writer
Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.
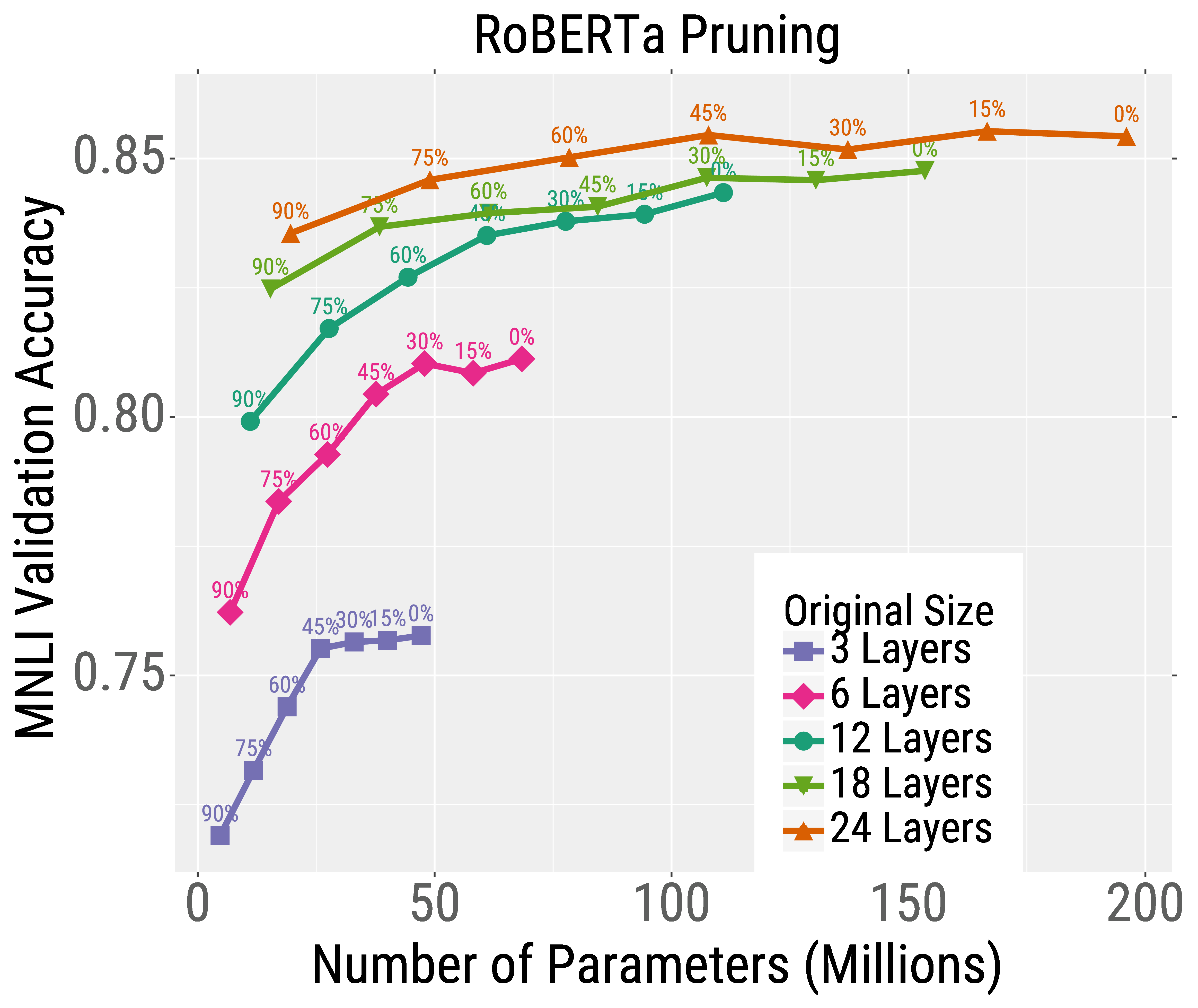
Speeding up transformer training and inference by increasing model size - ΑΙhub

Know what you don't need: Single-Shot Meta-Pruning for attention heads - ScienceDirect
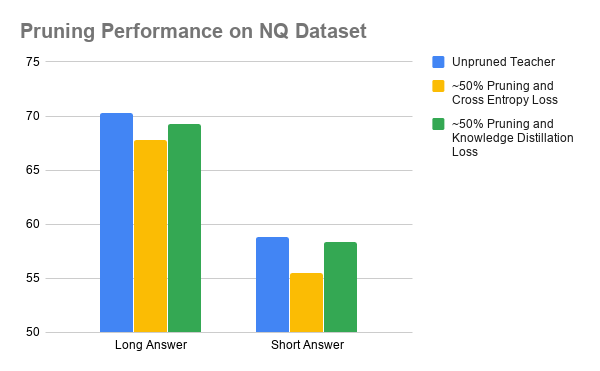
All The Ways You Can Compress Transformers
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Distillation and Pruning for GEC Model Compression - Scribendi AI

BERT compression (2)— Parameter Factorization & Parameter sharing & Pruning, by Wangzihan

PDF] EBERT: Efficient BERT Inference with Dynamic Structured Pruning

Jeannie Finks on LinkedIn: Uhura Solutions partners with Neural
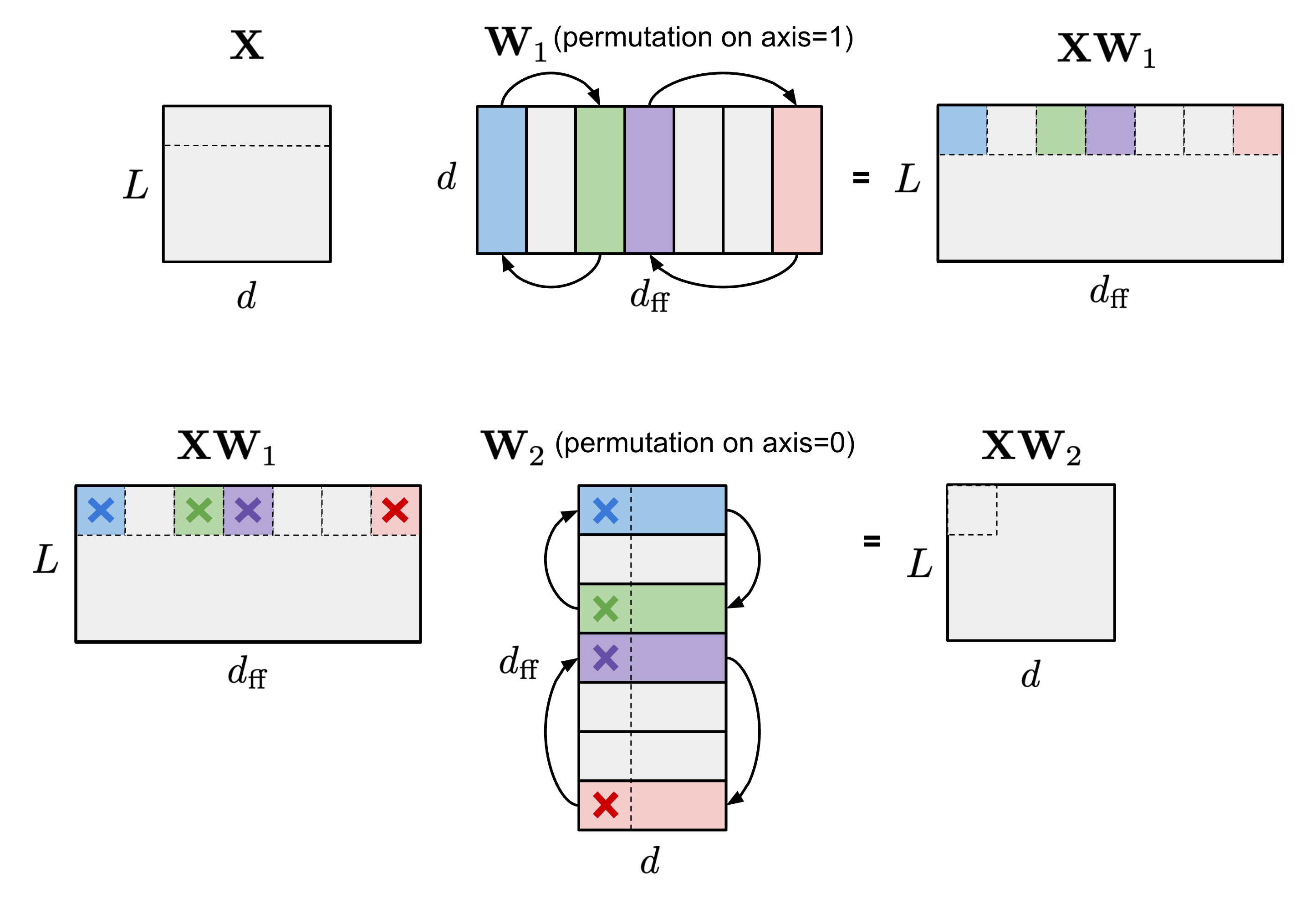
Large Transformer Model Inference Optimization
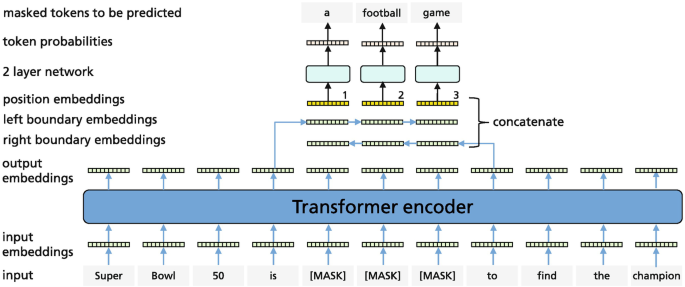
Improving Pre-trained Language Models

Delaunay Triangulation Mountainscapes : r/generative
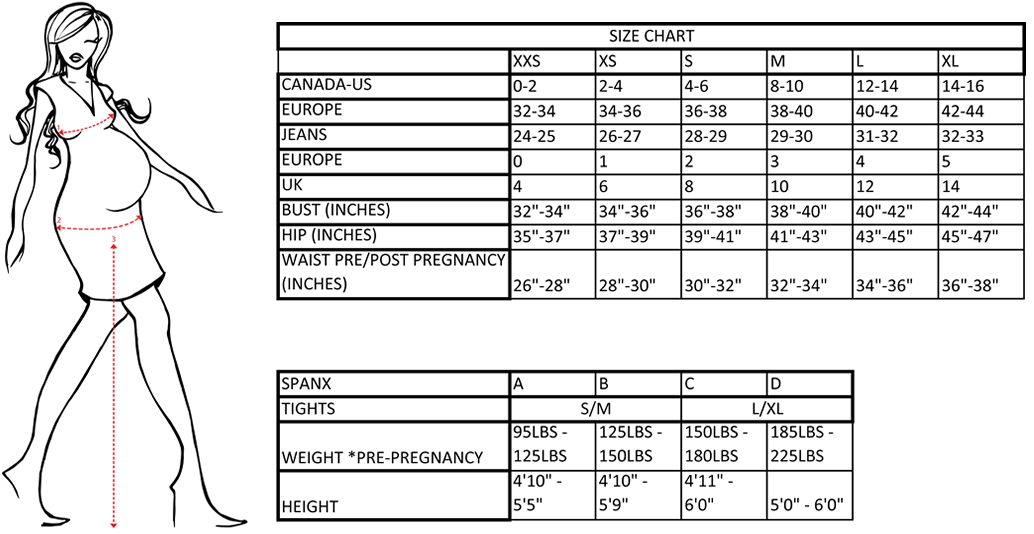
- Maternity Size Chart Motherhood Closet - Maternity Consignment
- Banner Pedagógico Escolar - Tabuada Multiplicação em Promoção na Americanas

- Connie Crawford Plus Pajama Butterick B6262 Miss XS-XL, Modern Fit, Ready-to-wear Sizing, Pajama Separates, Loose Fit Loungewear, Knit Pj's - Australia

- Travesseiros Super Confort + Protetores RL CAPAS - Conforto e Proteção - Enxovais Ibitinga

- When you create the most perfect personalised hand luggage bag

- Maya Angelou quarter: Rosie Rios on championing historical women

- Women's Essentials Deep U Multi-Way Convertible Push Up Plunge Bra

- Baby And Toddler Girls Mommy And Me Short Sleeve Floral Print Clip

- High-rise leggings in multicoloured - Mugler

- Women Sexy Compression Pantyhose Tights Leggings Stockings Socks - China Cotton Socks and Sport Socks price
