Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

By A Mystery Man Writer
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

Data engineering and intelligent computing : proceedings of IC3T 2016 978-981-10-3223-3, 9811032238, 978-981-10-3222-6

Apache Kafka With Spark Structured Streaming With Emma Liu, Nitin Saksena, Ram Dhakne, Current 2022

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

PDF) Spark Performance Tuning

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

Cranking the Voltage on Spark: Achieve Peak Performance with Optimization, by BlackRockEngineering
High Performance Spark, 2nd Edition [Book]

miro./v2/resize:fit:1400/1*QmlphAQ0u8_VB

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Azarudeen S on LinkedIn: #spark #apachespark #spark #optimization #interviewpreparation

Apache Spark Optimization Toolkit
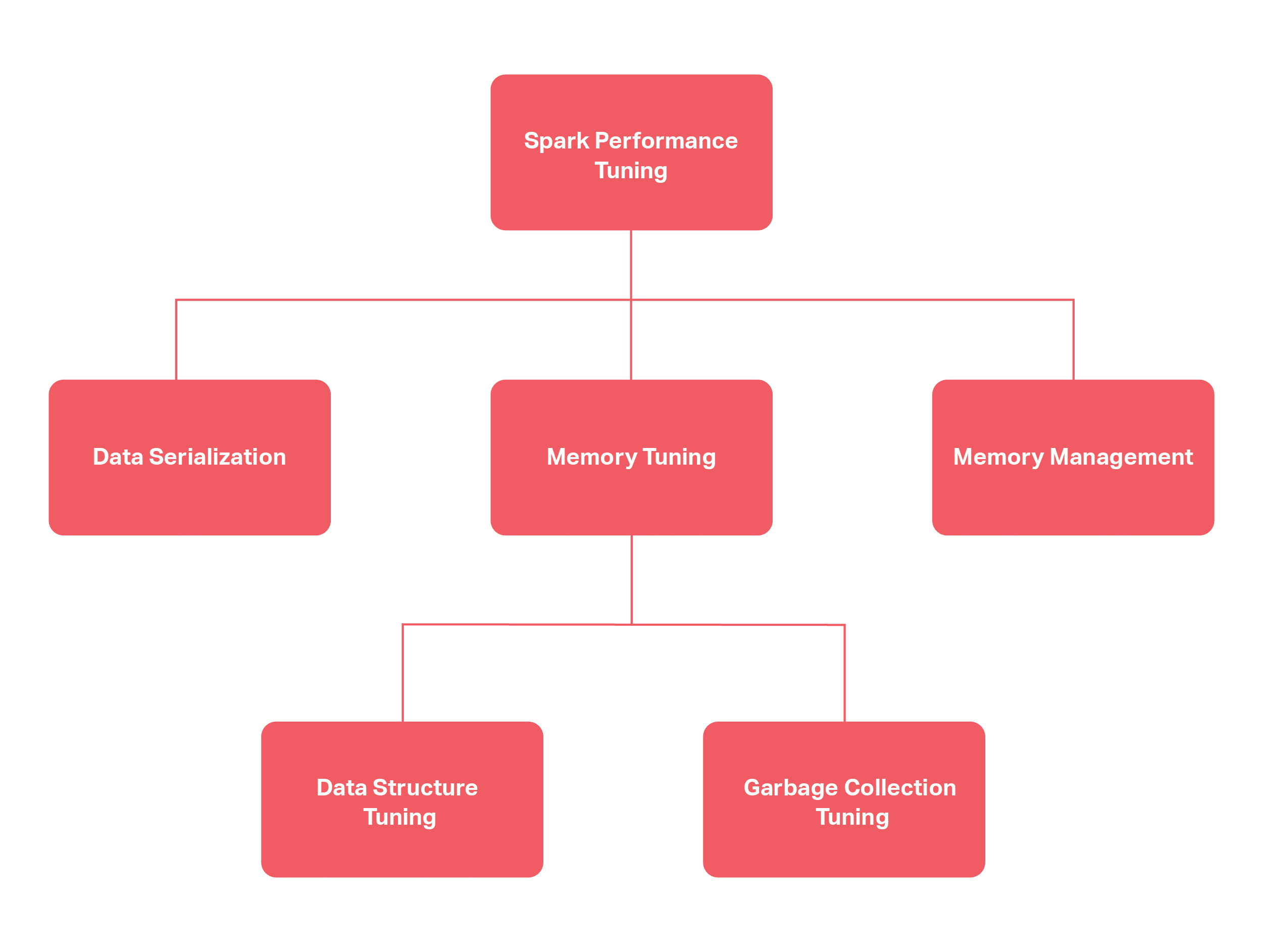
Spark Tuning: Spark Resource Optimization
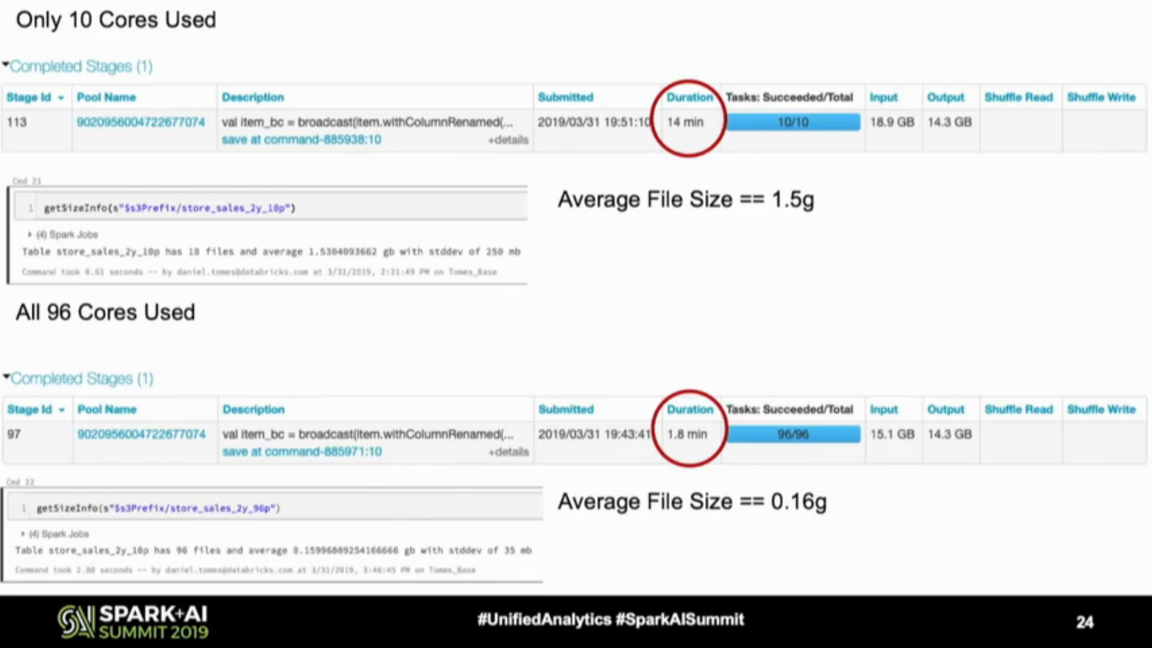
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark

Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering
- Wedgie ouchies. For girls only

- Hee321 User Profile

- The Wedgie Quiz: What wedgie should you get? Your Result: Front Wedgie The results are in“.
- PhoneAMommy on X: Do you need #diaperpunishment ? let the #dommemommy at serve up some #abdlpunishment come meet us 1 888 430-2010 / X

- Summary of Big Nate: A Good Old-Fashioned Wedgie: Trivia/Quiz for Fans

- Buy 3 Comfy Soft Youth Boys Protective Athletic Sports Cups – The

- A Dress For Every Body – The Vintage Woman

- MSemis Women Adult Criss Cross Shelf Bra Ballet Dress Dancer Ballet Leotards for Women Ballerina Gymnastics Leotard Dancewear - AliExpress

- Happy Birthday Tatum: Tatum Happy Birthday GIFT . Sketchbook Cute Cat on cover. Large Unlined Blank Papers For Sketching, Drawing & Doodling ,110 Pages, 8.5 x 11,Great For Painting, Crayon Coloring and

- Pin on Quick Saves
